Automatic scaling
Scaling is the ability to adjust available resources to meet client demands. Scale and Enterprise (with standard 1:4 profile) tier services can be scaled horizontally by calling an API programmatically, or changing settings on the UI to adjust system resources. These services can also be autoscaled vertically to meet application demands.
Automatic vertical scaling is available in the Scale and Enterprise plans. To upgrade, visit the plans page in the cloud console.
Scale and Enterprise tiers supports both single and multi-replica services, whereas, Basic tier supports only single replica services. Single replica services are meant to be fixed in size and don't allow vertical or horizontal scaling. You can upgrade to the Scale or Enterprise tier to scale your services.
How scaling works in ClickHouse Cloud
Currently, ClickHouse Cloud supports vertical autoscaling and manual horizontal scaling for Scale tier services.
For Enterprise tier services scaling works as follows:
- Horizontal scaling: Manual horizontal scaling will be available across all standard and custom profiles on the enterprise tier.
- Vertical scaling:
- Standard profiles (1:4) will support vertical autoscaling.
- Custom profiles (
highMemoryandhighCPU) do not support vertical autoscaling or manual vertical scaling. However, these services can be scaled vertically by contacting support.
Scaling in ClickHouse Cloud happens in what we call a "Make Before Break" (MBB) approach. This adds one or more replicas of the new size before removing the old replicas, preventing any loss of capacity during scaling operations. By eliminating the gap between removing existing replicas and adding new ones, MBB creates a more seamless and less disruptive scaling process. It is especially beneficial in scale-up scenarios, where high resource utilization triggers the need for additional capacity, since removing replicas prematurely would only exacerbate the resource constraints. As part of this approach, we wait up to an hour to let any existing queries complete on the older replicas before removing them. This balances the need for existing queries to complete, while at the same time ensuring that older replicas do not linger around for too long.
Vertical auto scaling
Automatic vertical scaling is available in the Scale and Enterprise plans. To upgrade, visit the plans page in the cloud console.
Scale and Enterprise services support autoscaling based on CPU and memory usage. We constantly monitor the historical usage of a service over a lookback window (spanning the past 30 hours) to make scaling decisions. If the usage rises above or falls below certain thresholds, we scale the service appropriately to match the demand.
For non-MBB services, CPU-based autoscaling kicks in when CPU usage crosses an upper threshold in the range of 50-75% (actual threshold depends on the size of the cluster). At this point, CPU allocation to the cluster is doubled. If CPU usage falls below half of the upper threshold (for instance, to 25% in case of a 50% upper threshold), CPU allocation is halved.
For services already utilizing the MBB scaling approach, scaling up happens at a CPU threshold of 75%, and scale down happens at half of that threshold, or 37.5%.
Memory-based auto-scaling scales the cluster to 125% of the maximum memory usage, or up to 150% if OOM (out of memory) errors are encountered.
The larger of the CPU or memory recommendation is picked, and CPU and memory allocated to the service are scaled in lockstep increments of 1 CPU and 4 GiB memory.
Configuring vertical auto scaling
The scaling of ClickHouse Cloud Scale or Enterprise services can be adjusted by organization members with the Admin role. To configure vertical autoscaling, go to the Settings tab for your service and adjust the minimum and maximum memory, along with CPU settings as shown below.
Single replica services cannot be scaled for all tiers.
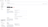
Set the Maximum memory for your replicas at a higher value than the Minimum memory. The service will then scale as needed within those bounds. These settings are also available during the initial service creation flow. Each replica in your service will be allocated the same memory and CPU resources.
You can also choose to set these values the same, essentially "pinning" the service to a specific configuration. Doing so will immediately force scaling to the desired size you picked.
It's important to note that this will disable any auto scaling on the cluster, and your service will not be protected against increases in CPU or memory usage beyond these settings.
For Enterprise tier services, standard 1:4 profiles will support vertical autoscaling. Custom profiles will not support vertical autoscaling or manual vertical scaling at launch. However, these services can be scaled vertically by contacting support.
Manual horizontal scaling
Manual horizontal scaling is available in the Scale and Enterprise plans. To upgrade, visit the plans page in the cloud console.
You can use ClickHouse Cloud public APIs to scale your service by updating the scaling settings for the service or adjust the number of replicas from the cloud console.
Scale and Enterprise tiers also support single-replica services. Services once scaled out, can be scaled back in to a minimum of a single replica. Note that single replica services have reduced availability and are not recommended for production usage.
Services can scale horizontally to a maximum of 20 replicas. If you need additional replicas, please contact our support team.
Horizontal scaling via API
To horizontally scale a cluster, issue a PATCH request via the API to adjust the number of replicas. The screenshots below show an API call to scale out a 3 replica cluster to 6 replicas, and the corresponding response.
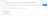
PATCH request to update numReplicas

Response from PATCH request
If you issue a new scaling request or multiple requests in succession, while one is already in progress, the scaling service will ignore the intermediate states and converge on the final replica count.
Horizontal scaling via UI
To scale a service horizontally from the UI, you can adjust the number of replicas for the service on the Settings page.
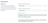
Service scaling settings from the ClickHouse Cloud console
Once the service has scaled, the metrics dashboard in the cloud console should show the correct allocation to the service. The screenshot below shows the cluster having scaled to total memory of 96 GiB, which is 6 replicas, each with 16 GiB memory allocation.

Automatic idling
In the Settings page, you can also choose whether or not to allow automatic idling of your service when it is inactive for a certain duration (i.e. when the service is not executing any user-submitted queries). Automatic idling reduces the cost of your service, as you are not billed for compute resources when the service is paused.
Adaptive Idling
ClickHouse Cloud implements adaptive idling to prevent disruptions while optimizing cost savings. The system evaluates several conditions before transitioning a service to idle. Adaptive idling overrides the idling duration setting when any of the below listed conditions are met:
- When the number of parts exceeds the maximum idle parts threshold (default: 10,000), the service is not idled so that background maintenance can continue
- When there are ongoing merge operations, the service is not idled until those merges complete to avoid interrupting critical data consolidation
- Additionally, the service also adapts idle timeouts based on server initialization time:
- If server initialization time is less than 15 minutes, no adaptive timeout is applied and the customer-configured default idle timeout is used
- If server initialization time is between 15 and 30 minutes, the idle timeout is set to 15 minutes
- If server initialization time is between 30 and 60 minutes, the idle timeout is set to 30 minutes.
- If server initialization time is more than 60 minutes, the idle timeout is set to 1 hour
The service may enter an idle state where it suspends refreshes of refreshable materialized views, consumption from S3Queue, and scheduling of new merges. Existing merge operations will complete before the service transitions to the idle state. To ensure continuous operation of refreshable materialized views and S3Queue consumption, disable the idle state functionality.
Use automatic idling only if your use case can handle a delay before responding to queries, because when a service is paused, connections to the service will time out. Automatic idling is ideal for services that are used infrequently and where a delay can be tolerated. It is not recommended for services that power customer-facing features that are used frequently.
Handling spikes in workload
If you have an upcoming expected spike in your workload, you can use the ClickHouse Cloud API to preemptively scale up your service to handle the spike and scale it down once the demand subsides.
To understand the current CPU cores and memory in use for each of your replicas, you can run the query below:
